
Background
The scientific community is facing a crisis of reproducibility: confidence in scientific results is damaged by concerns regarding the integrity of experimental data and the analyses applied to that data. Experimental integrity can be compromised inadvertently when researchers overlook some important component of their experimental procedure, or intentionally by researchers or malicious third-parties who are biased towards ensuring a specific outcome of an experiment. The scientific community has pushed for “open science” to add transparency to the experimental process, asking researchers to publicly register their datasets and experimental procedures. We argue that the software engineering community can leverage its expertise in tracking traceability and provenance of source code and its related artifacts to simplify data management for scientists. Moreover, by leveraging smart contract and blockchain technologies, we believe that it is possible for such a system to guarantee end-to-end integrity of scientific data and results while supporting collaborative research.
Introduction
As reported in a recent Nature article, the scientific research community faces a “reproducibility crisis”. 70% of the 1,576 scientists surveyed (from various fields, including chemistry, physics, earth and environmental science, biology, and medicine) reported that they had tried and failed to reproduce another scientist’s experiments. A 2012 review of 2,047 biomedical and life-science research articles that had been retracted found that 43% of those retractions were due to fraud (or suspected fraud). To maintain confidence in scientific results, we must ensure the integrity of the scientific workflow, from data collection to article publication.
Towards addressing this crisis, there has been a rise of online repositories to share scientific data, protocols, or findings. By publishing the data that led to a scientific result, researchers invite the reproduction of their experiments, even in cases where future researchers might have difficulties re-acquiring that same data (i.e., if specialized and expensive machinery were required). However, researchers have been slow to adopt such repositories: they are often seen as a burden, requiring time and effort to decide what data should be released and what form it should be. Moreover, some researchers may be wary to make large datasets available before they believe that they have achieved the maximum benefit (in terms of additional publications) from that data.
Even if researchers do choose to make their datasets public, this still does not solve the problem of data integrity. Who is to say that the data reported is unmodified? Or, in the event that it is advertised as modified, that it is in fact modified in the exact way described? If a researcher claims that they are releasing an entire dataset, are they? These challenges can arise even if we assume that no researchers would purposely make a false claim, as managing large ecosystems of data repositories is complex, and datasets are vulnerable to accidental corruption.
Historically, lab science data has been maintained in lab notebooks, where researchers might sign and date each page to attest to the authenticity of each step and collected data. But as data collection and analysis have become increasingly electronic, this record has begun to vanish. At the same time, provenance has itself grown complex, as research collaborations may be geographically distributed involving data from multiple researchers and analyses may make use of historical datasets. Moreover, the increasingly sophisticated scripts and tools for data analysis, which may themselves be shared or not shared, make it important to also maintain traceability links to the exact code used to analyze primary data, particularly if scripts are later improved or found to have defects.
Ideally, a data management system should:
- Support private collaboration — enabling researchers at the same lab or across institutions to collaborate in generating and analyzing unpublished private data before publication
- Support data collection and analysis workflows — ensuring that the system is well integrated into all steps of the data generation and analysis process and that its complexities do not become a barrier to adoption
- Support integration with the diverse data repositories already in use, as well as with the diverse authentication and authorization systems used by academic and research institutions
- Provide guarantees of the integrity of the data and results — maintaining immutable traceability links between the primary data collected, scripts used to analyze data, and the results of analyses
- Allow, but not require, full disclosure of datasets
- Allow the general public to easily discover datasets that have been publicly released
- Be open and decentralized, having no single point of failure or trust
Current scientific data management tends to focus on the dissemination of final results, with many repositories and approaches focusing on where those archives should be stored and indexed. What is lacking is a system that researchers can use in their lab, as they perform their research, to maintain immutable traceability links between the original data as captured, the transformations and analyses applied to it, and the results presented for publication.
We argue that by leveraging insights from software engineering and cryptography, we can provide the scientific research community with a data management infrastructure that meets all of these goals.
Proposed Solution
Filecoin provides a needed solution by making storage affordable, preventing vendor lock-in and fostering a culture of openness. By storing research objects in a decentralized repository, it becomes possible to share the entire research object with data and code, provide versioning, and ensure reproducibility.
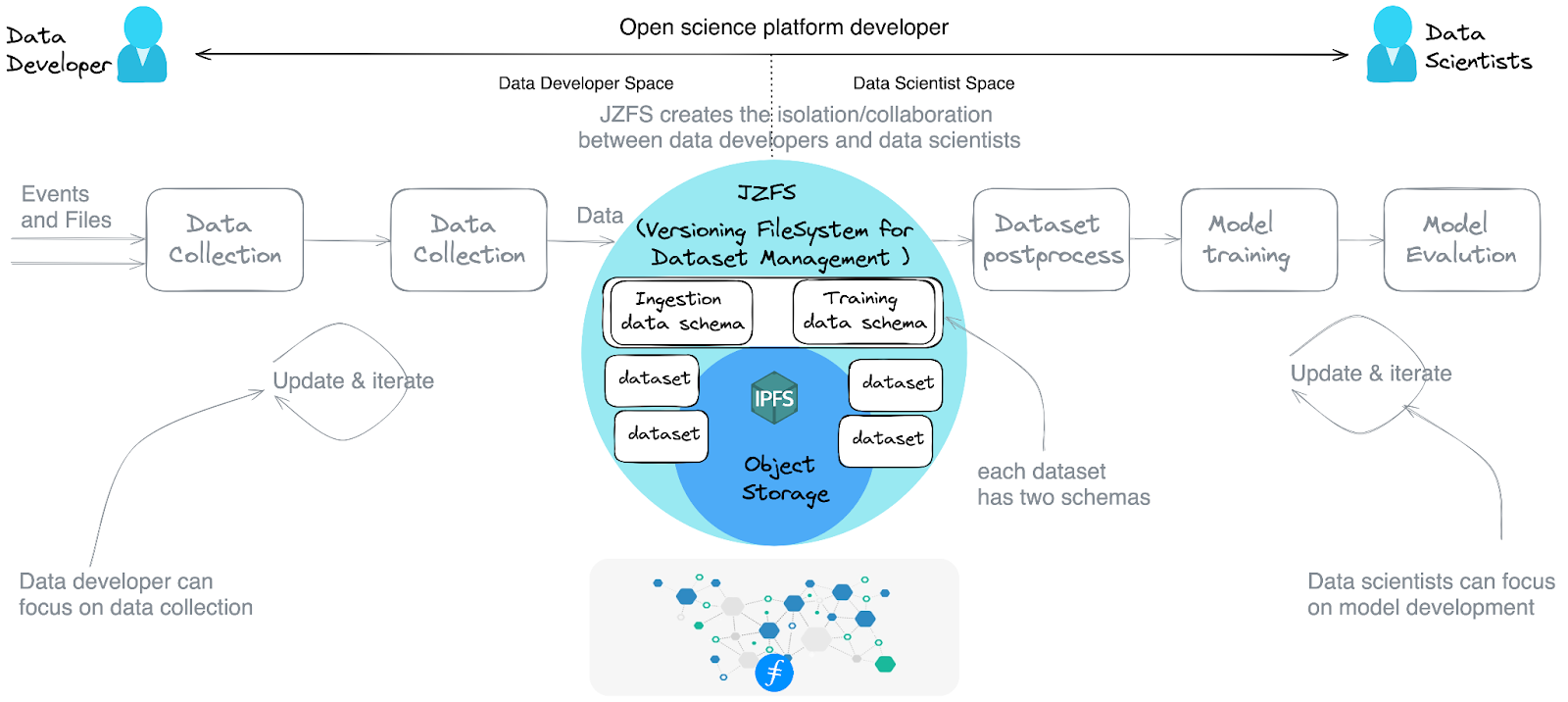
A dataset management component creates a good separation between training data collection and consumption by defining strongly typed schemas for both, which allows data development and model algorithm development to iterate in their own loop, thus expediting the project development.
Conclusion
The reproducibility crisis in scientific research highlights the urgent need for a robust, transparent, and secure data management system. By leveraging insights from software engineering and cryptographic technologies, we propose a solution that ensures end-to-end integrity of scientific data and results, while supporting collaborative research.
Ultimately, this approach not only addresses the current reproducibility crisis but also fosters a culture of transparency and collaboration in the scientific community. By making it easier to manage, share, and verify data, we pave the way for more reliable and trustworthy scientific discoveries, thereby restoring confidence in scientific research.
JiaoZiFS(JZFS) History
-
applied to the Decentralized Health - Institutional Grants 6 months ago of which the application is still in a pending state
-
accepted into Asia Round 7 months ago.
-
accepted into GG21 DeSci Round 7 months ago.
People donating to JiaoZiFS(JZFS), also donated to